

The Real Bottleneck Isn’t Model Intelligence
Every AI pilot I’ve seen in the past year stalled for the same reason. Not because the model was wrong. Because nothing around the model – the agentic AI orchestration layer – was ready for what the model produced.
CLOUDSUFI is a Google Cloud partner. We build agentic AI systems for enterprise clients in manufacturing, retail, and financial services. And over the past year, the question we keep getting asked has shifted. It used to be: is the model smart enough? We ran benchmarks, cited Bar exam scores, and measured code generation accuracy. For most enterprise use cases, that question is effectively closed. Frontier models are capable enough. The harder question is the one that replaced it: is your system built to handle what a capable model actually does?
We’re past the chatbot era. AI no longer waits for a human prompt, responds, and stops. Agentic systems reason, plan, and act across sequences of steps, often without a human in the loop. That’s a fundamentally different kind of software. And it has surfaced a problem that no amount of model improvement will fix: making individual agents smarter doesn’t make multi-agent systems more reliable. Sometimes it makes them less.
What is agentic AI orchestration?
Agentic AI orchestration is the software layer that governs how AI agents interact with each other — what order they run in, how they hand off work, what happens when one produces a wrong output, and how the system recovers. Without it, capable agents produce unreliable systems. Orchestration is what turns a collection of models into a production-grade pipeline.
That’s the problem worth solving right now.
Why Do Multi-Agent AI Systems Fail in Production?
When these systems break, the failure is almost never in the model itself. It’s in the connections between models: the handoffs, the assumptions, the absence of anything checking whether one agent’s output is actually fit for the next agent to consume.
Air Canada found this out in court. In 2024, British Columbia’s Civil Resolution Tribunal ruled that Air Canada was liable for its chatbot’s statements after the bot told a customer he could claim a bereavement discount after travel and apply for it retroactively. No such policy existed. The company had to pay. That wasn’t a model capability failure. It was a guardrail failure: nothing reviewed what the chatbot said before it reached a customer who built a decision around it. It was a single chatbot, not a multi-agent system. But it illustrates exactly what gets more dangerous at scale: without a validation layer, errors reach users before anyone catches them.
The technical term for what happens in multi-agent systems is the cascade effect, and it’s what keeps production deployments fragile. A minor hallucination from Agent 1 gets passed to Agent 2, which treats it as fact. Agent 2’s output, now built on a flawed premise, gets passed to Agent 3. By the time anyone notices, the corruption has touched every downstream step. One bad assumption, multiplied across five agents, can corrupt hundreds of records in a single run. We’ve seen it happen.

This is the gap between a demo and a production system. The demo works because one agent handles one task cleanly, in a controlled environment. Production fails because agents hand off to each other under real load, with real edge cases, and nothing playing conductor.
What Is Flow Engineering and Why It Replaces Prompt Engineering
The discipline we use to solve this is Flow Engineering: designing the multi-step workflows that govern how agents interact, not just what individual agents are told to do. The shift is from optimizing the player to writing the score.
Consider an orchestra. A single virtuoso sounds great alone. Put five of them in a room with no conductor and no sheet music, and what you get is noise. It doesn’t matter how talented each individual player is. The quality of the music comes from the structure around the musicians, not from the musicians themselves.
Agent systems work the same way. Prompt engineering makes individual agents better at their task. Flow engineering makes the system around them coherent. Without it, you have capable models producing outputs that no one is verifying, in sequences that no one is managing, at costs that no one is tracking.
Concretely, this means modeling agent workflows as stateful graphs rather than linear chains. Tools like LangGraph and Google’s Vertex AI Agent Builder let agents loop back when something looks wrong, branch based on output quality, and hand off to specialists without losing context. When a step fails, the system knows where it was. It doesn’t restart from zero and try again.
The Four Patterns That Make Agent Orchestration Reliable on Google Cloud
After several production deployments on Google Cloud, we’ve converged on four patterns that show up in every reliable system we’ve shipped. They’re not exotic. But skipping any one of them is how you end up back in demo territory.
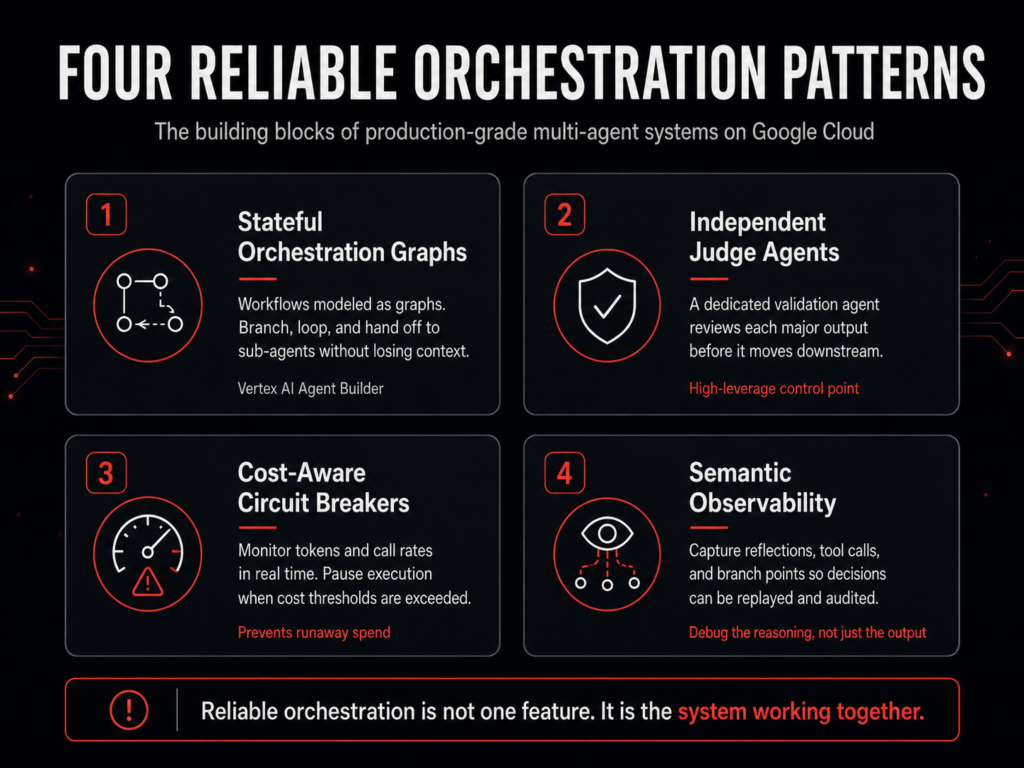
1. Stateful Orchestration Graphs
We model workflows as graphs using Vertex AI Agent Builder, Google Cloud’s native orchestration layer for production agentic systems. Agents can loop back, branch on conditions, and hand off to sub-agents without dropping context. This is the foundation. Everything else depends on the system knowing where it is at any given moment.
2. Independent Judge Agents
Every significant output gets reviewed by a dedicated validation agent before it moves downstream. This agent does one thing: check whether what it received matches what was specified. It catches hallucinations, format errors, and out-of-scope outputs before they can cascade.
Of the four patterns, this one has the highest leverage. A single judge agent sitting between steps 2 and 3 of a pipeline has caught errors that would otherwise have compounded across four more agents before anyone noticed. It also produces a structured audit trail. For financial services clients operating under strict record-keeping requirements, and for any CTO accountable to a compliance team, that trail is often the difference between a system you can defend and one you can’t.
3. Cost-Aware Circuit Breakers
Traditional software doesn’t burn money when it loops. Agentic systems do. A runaway reasoning loop can consume a month of API budget in under an hour while appearing to work normally from the outside. We put middleware in place that tracks token usage and call rates in real time. When an agent exceeds its expected cost envelope, execution pauses and a human gets alerted. We’ve pulled clients back from five-figure surprise bills with this.
4. Semantic Observability
Standard logs tell you what happened. They don’t tell you why an agent made the decision it made, which tool call it chose, or where in its reasoning chain it went sideways. Semantic observability means recording every reflection, every tool invocation, every branch point, in a format you can replay and audit. When something breaks in production (and it will), you need to be able to reconstruct the reasoning, not just the output. Without this, debugging a multi-agent system is guesswork with expensive stakes.
Why the AI Platform Team Model Reduces Enterprise AI Risk
The enterprises getting real value from agentic AI aren’t the ones with the most agents. They’re the ones with a centralized team that owns the orchestration layer.
Call it an AI Platform Team. It’s usually small: four or five engineers at the start, scaling with the organization. They sit under the CTO office or central platform engineering. They own the framework every business unit builds on: the guardrails, the validation patterns, the observability tooling, the cost controls, and the data security and governance standards that make agentic systems safe to run in regulated environments. Individual teams build agents on top of their platform. They don’t start from scratch.
The alternative is every team reinventing the same infrastructure independently. When something breaks in one team’s agent stack, nobody else learns from it. When costs spike, each team discovers the problem separately. The failures don’t compound across teams, but neither does the knowledge.
This model isn’t new. It’s exactly what made platform engineering teams effective during the DevOps shift: shared tooling, golden paths, governance that didn’t slow teams down but gave them something solid to build on. Agentic AI is going through the same transition now. The teams that figure out the platform layer first will move faster than those who let a hundred individual teams figure it out on their own.
What Orchestrated Autonomy Looks Like in Practice
The goal here isn’t maximum automation. It’s appropriate automation: knowing which decisions an agent can make reliably, and which ones still need a human.
We think about this as three operating modes, not a binary:
Ambient agents run continuously in the background, monitoring feeds, flagging anomalies, surfacing patterns a human might miss. They don’t need to ask permission. They surface what’s worth looking at.
Supervised agents handle defined tasks autonomously but stop before irreversible actions. Before posting an output, sending a communication, or writing to a record, they hand off to a human for sign-off. The agent does the work; the human makes the call.
Collaborative agents work alongside people in real time, proposing next steps, handling the mechanical parts, letting the human focus on judgment.
The human role shifts from doing tasks to reviewing outcomes. That’s a meaningful change in how teams operate, and it’s only safe when the orchestration underneath it is solid.
One manufacturing client we work with had already driven 98% process efficiency gains through data modernization. When we layered a supervised agent system on that foundation, document processing time dropped by more than 60%. The model didn’t change. The orchestration layer was what unlocked the second wave of value.
That’s the pattern we see repeatedly. The model gets you to the demo. The orchestration layer gets you to production.
Is Your Enterprise Ready for Agentic AI Orchestration?
Before your next pilot, three things worth pressure-testing:
If your lead agent produces a wrong output at step 2, does anything catch it before step 5, or does it compound silently until someone notices the damage?
Do you have visibility into what your agents are reasoning, or only what they output? If something goes wrong, can you reconstruct why?
If an agent loop runs unchecked for 30 minutes, what does that cost you in compute, data integrity, and time to remediate?
If any of those don’t have a clear answer, the orchestration layer needs attention before the agents do.
CLOUDSUFI‘s AI team works with enterprise organizations to design, build, and operate agent systems on Google Cloud, from the orchestration architecture to the observability layer. Our orchestration readiness assessment is a focused engagement, typically two to four weeks, with your CTO, CAIO, or Head of AI. We map your current architecture against these four patterns, identify where the gaps are, and deliver a prioritized roadmap with concrete next steps. Talk to our team to get started.
About the Author
Suhani Gupta is Manager – Marketing & Communications at CLOUDSUFI, where she leads brand storytelling, executive thought leadership, and enterprise marketing initiatives focused on data, AI, and emerging agentic systems. Her work centers on translating complex AI and technology narratives into clear, high-impact communication for enterprise decision-makers, while building category authority across digital, editorial, and event-led channels. She specializes in brand strategy, content systems, executive positioning, and B2B technology marketing for AI-first enterprises.
